
Comparing Clustering against Deep-Learning for Semantic Code Clone Detection
Absract:
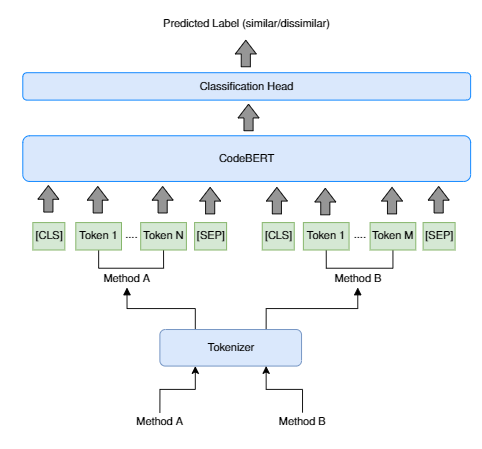
Semantic code clone detection involves the detection of functionally similar code fragments which may otherwise be lexically, syntactically, or structurally dissimilar. The detection of semantic code clones has applications in aspect mining and product line analysis. Semantic code clones have recently been used by a code recommendation system called FACER to model commonly co-occurring functionality across multiple software projects for recommending related code. In this paper, we compare the semantic code clone detection performance of FACER's API usage similarity-based clustering approach (FACER-CD) against a deep-learning based approach which uses a pre-trained programming language model called CodeBERT. We perform our evaluation on two datasets; a benchmark dataset of Java code clones (BigCloneBench) and another dataset consisting of Java code from Android applications. Our experiments indicate that CodeBERT outperforms FACER-CD on the BigCloneBench dataset by a 33% higher accuracy. However, FACER-CD outperforms CodeBERT by a 31% higher accuracy on the Android dataset. We find that by training CodeBERT on the Android dataset, the difference of accuracy between FACER-CD and CodeBERT is minimized, with CodeBERT outperforming FACER-CD by a 6% higher accuracy and FACER-CD outperforming CodeBERT by a 1% higher precision. Furthermore, we observe that CodeBERT requires a significantly higher amount of time than FACER-CD to give results on the same dataset. Our results can help researchers choose between deep learning-based models and clustering-based approaches for clone detection depending on their performance requirements.
Zoom: https://lums-edu-pk.zoom.us/j/92932127612?pwd=a1ZvRXY3OVMrZ2lpeEhFcEpOZGlkdz09
Meeting ID: 929 3212 7612
Passcode: 366438
![]()
Connect
![]()
![]()
![]()
![]()
![]()